
Introduction
Site Reliability Engineering (SRE) emerged at Google in the early 2000s as a discipline that applied software engineering principles to operations. By focusing on automation, observability, and proactive reliability design, SRE introduced a measurable and engineering approach to running large scale distributed systems.
As cloud adoption accelerated, these practices expanded across industries. They were influencing DevOps, platform engineering, and modern organizational operating models. Traditional models typically rely on self-managed infrastructure, custom monitoring stacks, manual fail-over processes, and ad hoc automation. Further more, Azure SRE shifts this burden to platform-integrated capabilities, reducing operational complexity while improving reliability baselines.
Where traditional SRE must design failover or autoscaling manually, Azure provides managed resiliency:
• Autoscale rules built directly into App Services and AKS node pools.
• Zone-redundant storage, databases, and networking.
• Traffic Manager and Front Door for global routing.
• Managed Kubernetes control planes and disaster recovery replication.
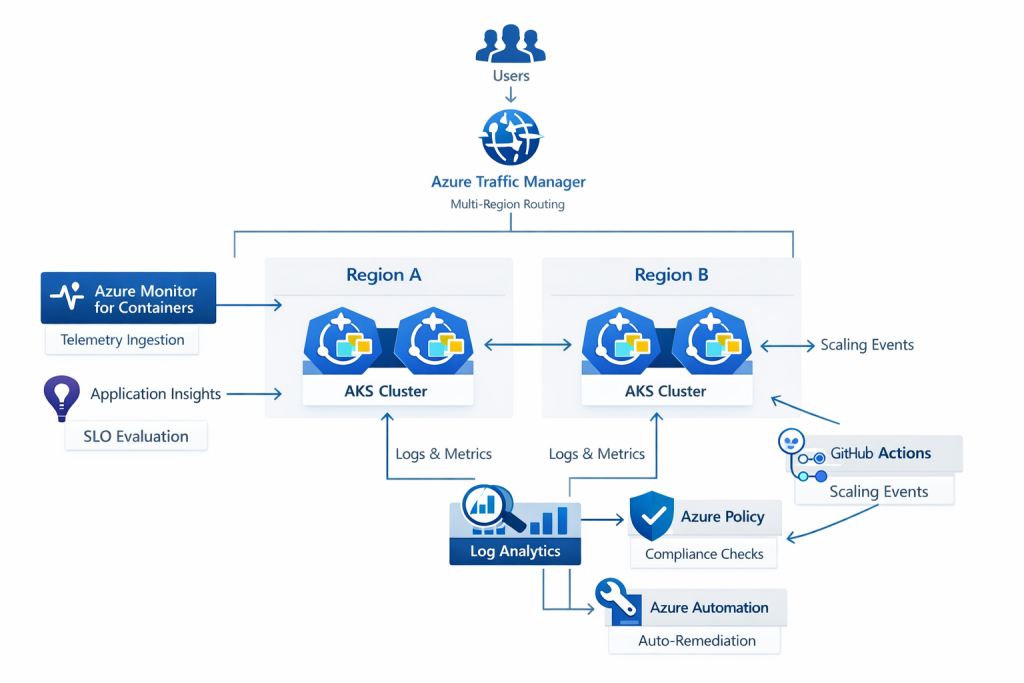
It is particularly effective for:
• Cloud migration with automated operational guardrails
• Micro-services architectures deployed on Azure Kubernetes Services
• High-throughput API workloads using App Services
• Mission-critical systems requiring multi-region resilience
• Data platforms with automated tuning, failover, and performance insights
The service takes the original concepts and maps it directly to Microsoft Azure’s platform capabilities. It is grounded with the knowledge from Cloud Adoption Framework (CAF) and Well-Architected Framework (WAF) for Azure. Azure SRE aligns built-in observability, auto-remediation, policy enforcement, and multi-region resiliency patterns within a unified operational model.
Learn more:
Azure SRE Agent
Cloud Adoption Framework for Azure
Cloud adoption in the era of accelerated Digital Transformation (ITuziast)
Capabilities of Azure SRE
Its practices leverage the Azure’s built-in observability, automation, and resiliency features. Services like, Azure Monitor, Log Analytics, and Application Insights provide real time telemetry for logs, metrics, distributed traces, dependencies, and user analytics. These tools support defining SLIs and evaluating SLO compliance across environments.
Automation operation is a core Azure SRE capability. With services like, Azure Automation, Logic Apps, GitHub Actions, and Azure Functions, enables autonomous healing, scaling, and remediation triggered by alerts and/or policy.
On top of that, governance enhancements such as Azure Policy, Defender for Cloud, and Azure Resource Graph enforce operational baselines and configuration consistency. Finally, these services have a platform-native resiliency. That includes availability zones, autoscaling, global load balancing, and built-in DR capabilities. All that, put together, provides a reliable foundation for workloads running on cloud-native application and data services.
Common terminology used in SRE
As part of the measurements of reliability engineering, we use:
- Service-level Indicator (SLI): A quantitative measure that reflects the performance of a service. Examples include request latency, error rates, and system throughput. They help track how well a service is performing against its goals.
- Service-level Objective (SLO): An internal target for a service’s performance, defined using SLIs. It sets specific goals for reliability, such as 99.9% uptime over a month. They help teams understand the level of service they aim to provide.
- Service-level Agreement (SLA): A formal contract between a service provider and customers that outlines expected service levels and penalties for not meeting them. These often reference the objectives (SLOs).
- Error budgets: Allowed unreliability of specific service, before it impacts users. It represents the difference between Service-level Objective and actual performance
So what is the correlation between them? Service-Level Indicator (SLI) measure actual performance, Service-Level Objective (SLO) set internal targets based on those measurements, and Service-Level Agreement (SLA) define commitments to customers.
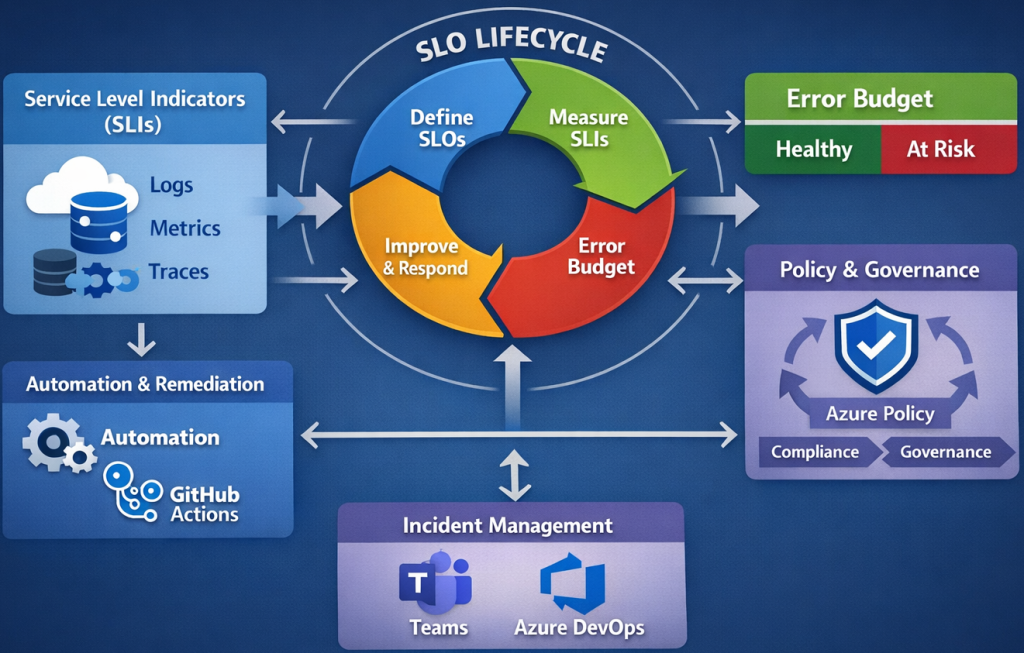
Azure SRE defines SLIs using metrics captured by Azure Monitor (metrics, logs), Application Insights (availability, performance, traces), and Log Analytics (custom queries). Common SLIs include request success rates, latency (p95/p99), CPU/memory saturation, dependency failures, queue length, or end to end transaction health.
On the other hand, SLOs represent the target reliability levels, such as “99.9% request success rate” or “latency p95 <150ms.” These are monitored continuously using dashboards and workload-specific workbooks. Azure SRE treats SLOs as contractual boundaries between reliability and development velocity.
Error budgets quantify the tolerable failure margin (1 minus the SLO). As a result of that, when error budgets are healthy, teams deploy new features freely. On the other hand, when error budgets are exhausted, deployment freezes or architectural hardening is enacted. This system ensures reliability remains a measurable, enforceable practice supported by Azure Monitor alerts, change analysis, and incident insights.
Example:
When SLA promises 99.9% uptime, the corresponding SLO might be set at 99.95% uptime, with the SLI measuring actual uptime. It he error budget allows 0.1% downtime, this means ~43min downtime per month is acceptable.
Roles and responsibilities
All of the Site Reliability Engineering functions, in Azure, align with Cloud Adoption Framework’s operating model and cross disciplinary skill sets. The Cloud Adoption framework maps these functions trough the RACI matrix (Responsible, Accountable, Consulted, Informed).
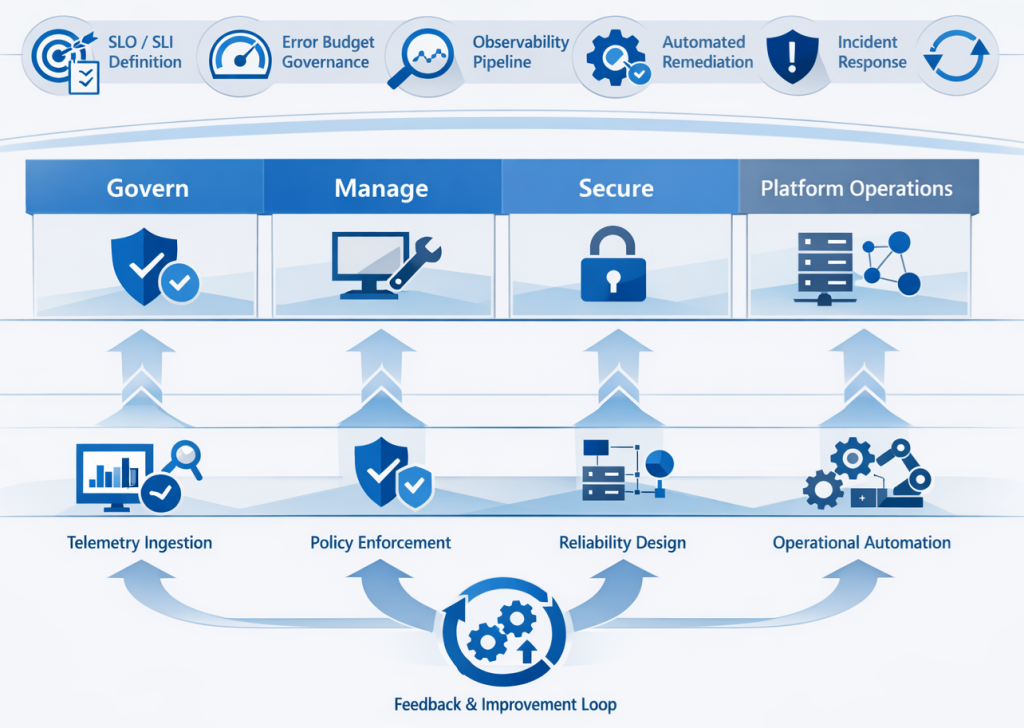
By all means, there will be overlap in accountability. Both frameworks state that one team must be accountable for reliability/governance. On the other hand, multiple teams may be responsible for the execution. While Azure SRE allow for temporary elevated access, the CAF requires governance guardrails. This can cause potential violation of policies. Furthermore, while CAF focuses on organizational culture shift and change management, the SRE is focused on technical reliability.
Typical Azure SRE roles are:
- Cloud SRE Engineer: Day-to-day reliability, troubleshooting and operations. This is a hands-on operator role.
- SRE Lead / Reliability Architect: Reliability strategy, architecture and resilience design. This role is deeply involved in design and governance.
- Observability Engineer: Monitoring, metrics, logging and tracking. This is operator role, specialized in telemetry.
- Automation / Platform Engineer: Automation, CI/CD pipelines, platform reliability. This role is focused on configuration management trough automation.
- Incident Manager (SRE-aligned): Incident response, coordination and communication. This is a operator role, focused on incident and escalation processes.
As a result of that, during implementation of Azure SRE with guidance from the Cloud Adoption Framework, think of the SRE roles as operation execution level. On the other side, the CAF roles will provide the organizational accountability and governance. All the migration and modernization roles are part of Cloud Adoption teams.
The following table provides comparison between these roles in the organization:
| Dimension | Azure Site Reliability Engineering | Cloud Adoption Framework for Azure |
|---|---|---|
| Primary focus | Reliability, incident response, automation | Cloud adoption, governance, org alignment |
| Role definition | Cloud SRE Engineer, SRE Lead / Reliability Architect, Observability Engineer, Automation / Platform Engineer, Incident Manager (SRE-aligned) | RACI matrix (Responsible, Accountable, Consulted, Informed) |
| Governance mechanism | Role-based access control (RBAC), identity and access management (IAM), agent/managed identities | RACI matrix, organizational structure |
| Accountability | Administrators approve elevated access | Centralized IT (or Center of Excellence) is accountable for the standards |
| Operational execution | Cloud SRE Engineer, Observability Engineer, Incident Manager (SRE-aligned) troubleshoot and automate | Cloud Adoption team members execute the operations |
| Collaboration | Cross-team approvals and access control | Cross-team RACI alignment |
Conclusion
Azure SRE drives improvements in several operational areas. IT helps organizations reduce the MTTR trough the automation of diagnostics and self-healing. The error budget, as proactive component, provides better governance model. It helps organizations identify at-risk workloads, before something happens. As a result of using managed services with built-in resiliency, organizations feel lower burden on their workload operations. Needless to say, that there can be significant cost efficiency when using operational baselines and intelligent scaling of those workloads.
It is also important to remember, the alignment between the Azure SRE and CAF principles. Be careful about the answers to “Who owns reliability?” question. It is important to avoid duplicate efforts during incidents. In that case, CAF might slow down the response with its approval chain (SRE is all about speed). Further more, the CAF assumes distributed responsibility and SRE centralizes operational expertise. This can cause bottlenecks in scaling the cloud adoption.
In certain cases, the technical metrics (telemetry, insights) is not aligned with the business KPIs (CSAT, revenue impact). Although the data is there, it doesn’t influence business decisions.
The policy definitions in CAF are not always automated, where policy enforcement in SRE is fully automated. This could create inconsistent policy enforcement in the organization, reliance on manual checks and glimpse of “Shadow IT” practices.
Over time, organizations processes will evolve and successfully mitigate these issues.



Be the first to comment