
I haven’t written anything in more details on the Azure Log Analytics, but some things popped-up in my mind few months ago. I think its time I consolidate them in a form of design consideration, of sorts.
Previous articles are in the Azure section.
As You might have noticed (if not, its time You do 🙂 ) the Azure Monitor is the core component for end-to-end collection, analysis, and acting on telemetry from our cloud and/or on-premises resources/services. All data collected, is stored in a repository called Log Analytics Workspace.
What is Log Analytics Workspace?
An central location where all the aggregated data, from various sources is collected and stored. Each data set is stored in tables, and it carries some unique properties in relation to the source of the data.
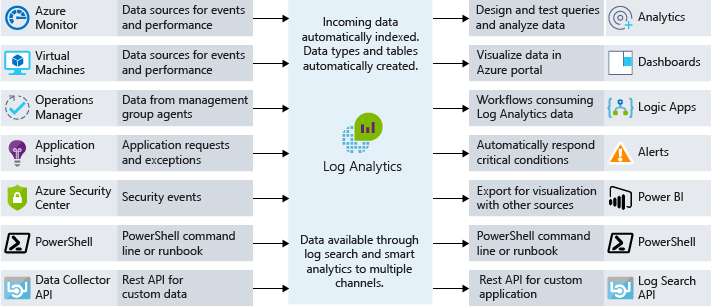
There can be more than one Log Analytics Workspace created, within the subscription. What do we connect to it, would be based on our preference, as well as some additional considerations.
For more information on hot the create one, check the following article.
Important design considerations
1. How many Log Analytics Workspace’s we need?
The usual answer is “It depends” 🙂 You see, the log analytics workspace is data store, located within a geography. The data resides in certain Microsoft Azure datacenter, where the back-end infrastructure is managed. Now, depending on the size of the organization as well as the IT Department’s organizational structure we might have different data collection, aggregation and analysis needs.
One of most common reasons, to have more than one workspace would be data sovereignty or compliance. We need to keep the data collected within a specific geography. Now, this will also help the cost side – data does not need to me “moved” to a different location, hence no egress traffic costs.
To be fair, I’ve seen this happen in a more decentralized IT Organizations as well. Dedicated IT teams operate with dedicated applications/services. Data is isolated, role based access control model is within a dedicated group – administrative and user (less overhead).
The draw back of the model is issues with data correlation and potential of creating some “blind spots”. Due to the “silo approach”, a broader view on the data is almost impossible.
Non-enterprise customers always opt-in for the centralized model – one to rule them all. All the data is aggregated in a single workspace. Now, over time, as additional services are added, the workspace will grow in size. We can control the cost side with tweaking the retention period and/or daily data cap. The role based access model will be simplified – smaller in-house teams or dedicated external support teams (MSP).
Worst case scenario is combining both models into a hybrid one. Due to some compliance and security audit requirements, both models can be used together. This creates complex, and high-maintenance configuration. It still has “blind spots”.
Use the Centralized approach – on to rule them all. In case there is no regulatory and or compliance issue this is the way to do it.
2. What about data collection?
Now this boils down to a simple subset of questions (if I may use the term “simple”). The assumption would be that monitoring strategy exists.
The strategy would follow the line of specific areas (i.e. health of applications, user experiences, alerts and incident management, integration, visibility of data etc). For more information look at Cloud monitoring guide: Formulate a monitoring strategy from Cloud Adoption Framework.
It’s important to know: what needs to be monitored? We usually focus on the mission critical applications/services and the dependent components. We need to be precise on what signals are we looking at and collect the ones we need. In this way, we optimize the number data collection points. This will help us analyze and/or display the data we actually need. On the operations side we will maintain better focus on whats important, as well as the reduce cost on the workplace.
Once we determine what needs to be collected, we need to figure out the how part. Yes, we can store petabytes of data, we don’t have limits in the scaling and/or capacity. Hence, a single Log analytics Workspace would do the trick. Never the less, You need to be aware of the Azure Monitor service limits.
For example, uncompressed data ingestion is ~6Gb/min (~500Mb/min compressed). This amasses to 4Tb/day ingestion limit. If you exceed that limit, then consider the Azure Monitor Logs Dedicated Clusters option.
3. How do we manage the access control?
Simple answer would be trough Azure role-based access control (Azure RBAC). In this way, we only grant access right as the IT Operations personnel needs. this approach will be aligned with Your IT Organizational structure, following least privilege access rights principle.
As far as the access mode determines how that user will access the Log analytics Workspace, and what’s the scope. We have two options, for gaining access to the data in this case:
- Workspace scope (context) – Gives access to all he log data collected within a workspace. Queries can be executed on all data in the workspace. Any Workspace created before March 2019 has this as default setting
- Resource scope (context) – Gives more granular access to specific resource, resource group, and/or subscription. Queries can be executed within that particular scope only. Any Workspace created after March 2019 has this as default setting.
Queries will work if the proper association with the resource is made. This is the Resource scope limitation. For example, resources outside of Azure can be accessed and log collection will occur with the use of Azure Arc for Servers.
So when, to use which scope? Workspace scope is relevant to central administrative operations. This means any type of configuration of the workspace (Owner access rights) – connecting agents, configuration of the data collection, assigning roles etc. Resource scope (Read or Contributor access rights) is more related to specific monitoring operations roles (Application teams, Resource Administrators, etc).
The Resource scope access supersedes the Workspace scope access, in case the user has both assigned.
If You need to change the access control mode, look at the following article for more details.
Conclusion
What’s the bottom line, all things considered? In case we have a clear situation – no regulatory/compliance restrains, no need to have multi-region data collection points. Go for singe Log Analytics Workspace.
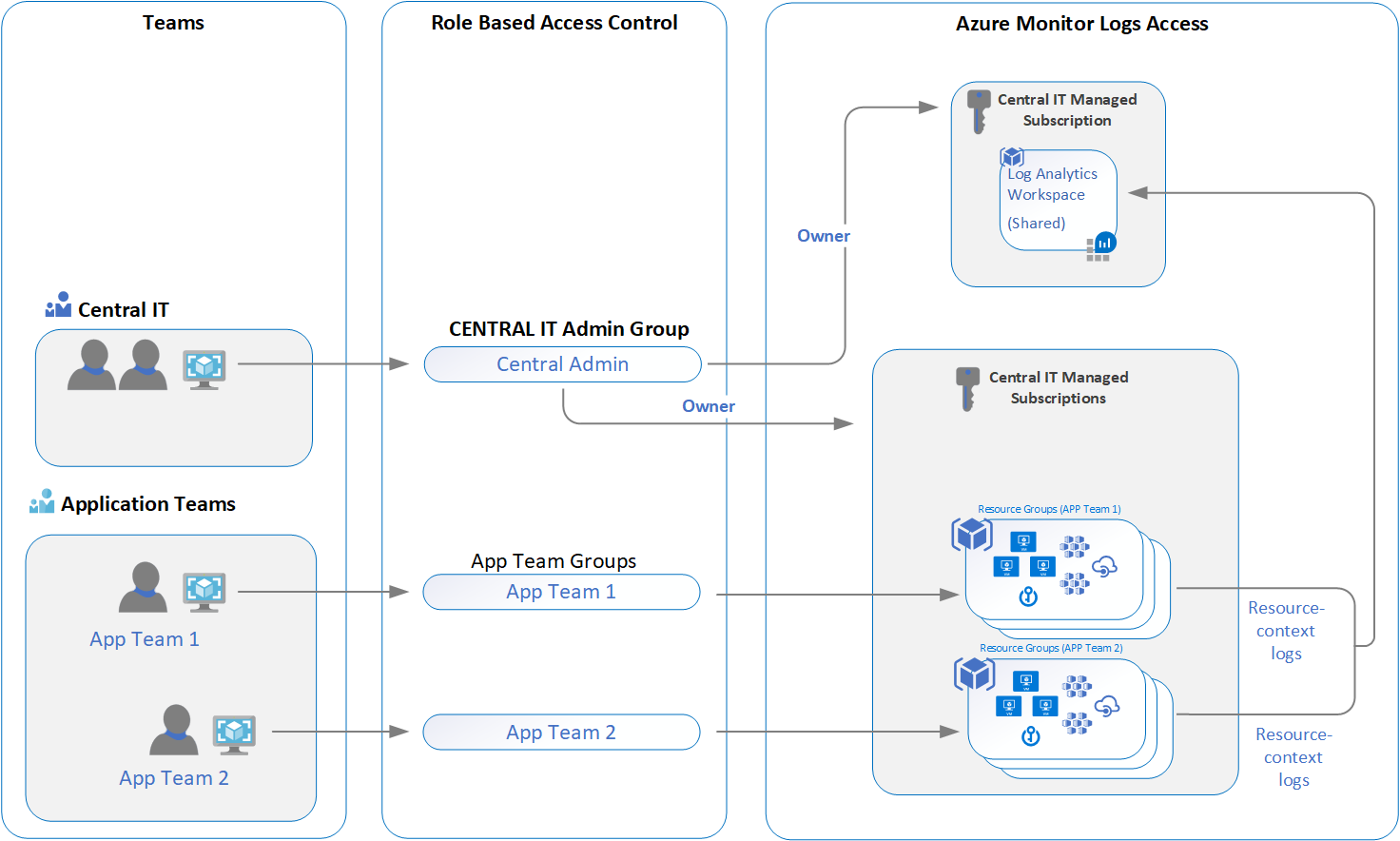
Operations wise its smart choice. We define what teams will perform which tasks, define the roles and assign them within a scope. Centralized model will work. Not only for IT Operations Teams, but for specific Application Teams activities as well.
Role based access will be assigned within the necessary scope (Workspace or Resource). The users are members to specific security groups, and then on those security groups we assign the built-in Azure RBAC roles, and we set the scope.
Data collection will be centralized. Any queries will be executed within the secuirty context based on effective access rights. Further more, once the Workspace design is defined and deployed (remember the strategy mentioned before), we can enforce specific policies to ensure compliance, as well as perform remediation/mitigation of issues (trough Azure Policy).



Be the first to comment